Deep Dive: Table Bloat trong PostgreSQL và Chiến lược Tối ưu Storage
Gần đây tôi có nghiên cứu sâu về cách PostgreSQL quản lý lưu trữ và bắt gặp một chủ đề cực kỳ thú vị: Table Bloat. Với những ai làm việc với dữ liệu lớn, việc “scale up” dung lượng ổ cứng chỉ là giải pháp bề nổi. Để tối ưu hóa thực sự về chi phí hạ tầng (đặc biệt là trên Cloud với mô hình provisioned IOPS/storage) và cải thiện hiệu năng I/O, chúng ta buộc phải hiểu tường tận cách Postgres ghi và xóa dữ liệu ở mức vật lý.
Dưới đây là tổng hợp những ghi chép (notes) của tôi dựa trên bài viết gốc từ Tiger Data về cơ chế lưu trữ và cách xử lý Bloat.
1. Tại sao phải quan tâm đến Storage Optimization?
Ngoài bài toán chi phí (Cost) hiển nhiên, vấn đề cốt lõi của việc phình to dữ liệu nằm ở Hiệu năng (Performance). Khi database chứa quá nhiều dữ liệu “rác” (bloat), các thao tác quét bảng (sequential scans) và chỉ mục (index scans) sẽ tốn nhiều I/O hơn mức cần thiết. Truy vấn chậm đi không phải vì dữ liệu nhiều lên, mà vì database phải đọc qua quá nhiều vùng không gian chết.
2. Giải phẫu Storage trong PostgreSQL (Essential Concepts)
Để hiểu tại sao database chậm đi khi bị phình, chúng ta cần gạt bỏ tư duy về các dòng dữ liệu logic (Excel style) và nhìn vào cách PostgreSQL tổ chức vật lý.
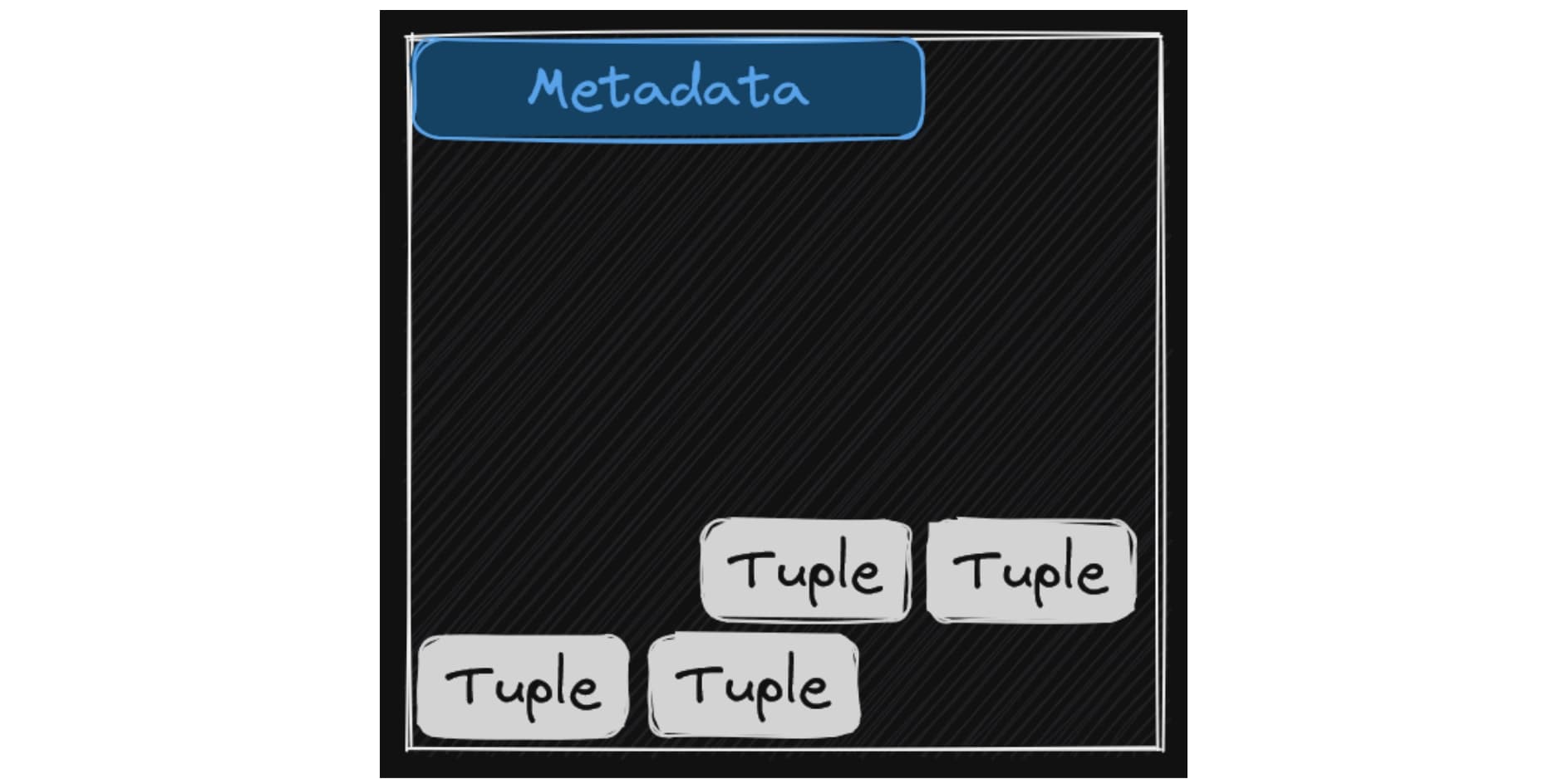
Hãy hình dung Database của bạn giống như một Cuốn sổ tay ghi chép khổng lồ.
- Tuple (Dòng dữ liệu) - Là “Nội dung”: Tuple chính là một dòng (row) dữ liệu cụ thể. Ví dụ:
{ID: 1, Name: "An"}. Nó giống như một dòng chữ bạn viết vào cuốn sổ. - Page (Trang dữ liệu) - Là “Vật chứa”: Ổ cứng máy tính không đọc từng dòng chữ lẻ tẻ, nó đọc từng khối (block). PostgreSQL quy định mỗi khối này là một Page (mặc định 8KB). Nó chính là một trang giấy trong cuốn sổ tay. Bạn bắt buộc phải viết các dòng chữ (Tuple) lên trang giấy (Page) này.
Cơ chế I/O: “Bê cả container”
Đây là điểm mấu chốt. Khi bạn chạy SELECT * FROM Users WHERE ID = 5, database không nhảy vào nhặt đúng dòng đó ra.
Nó xác định ID=5 nằm ở Page số 100.
Nó load toàn bộ Page số 100 (8KB) từ ổ cứng lên RAM.
Sau đó CPU mới lọc trong Page đó để lấy ra Tuple bạn cần.
Quy tắc: Database thao tác trên Page. Muốn lấy 1 món hàng (Tuple), phải cẩu cả cái container (Page) xuống.
Cơ chế MVCC và sự hình thành “Dead Tuples”
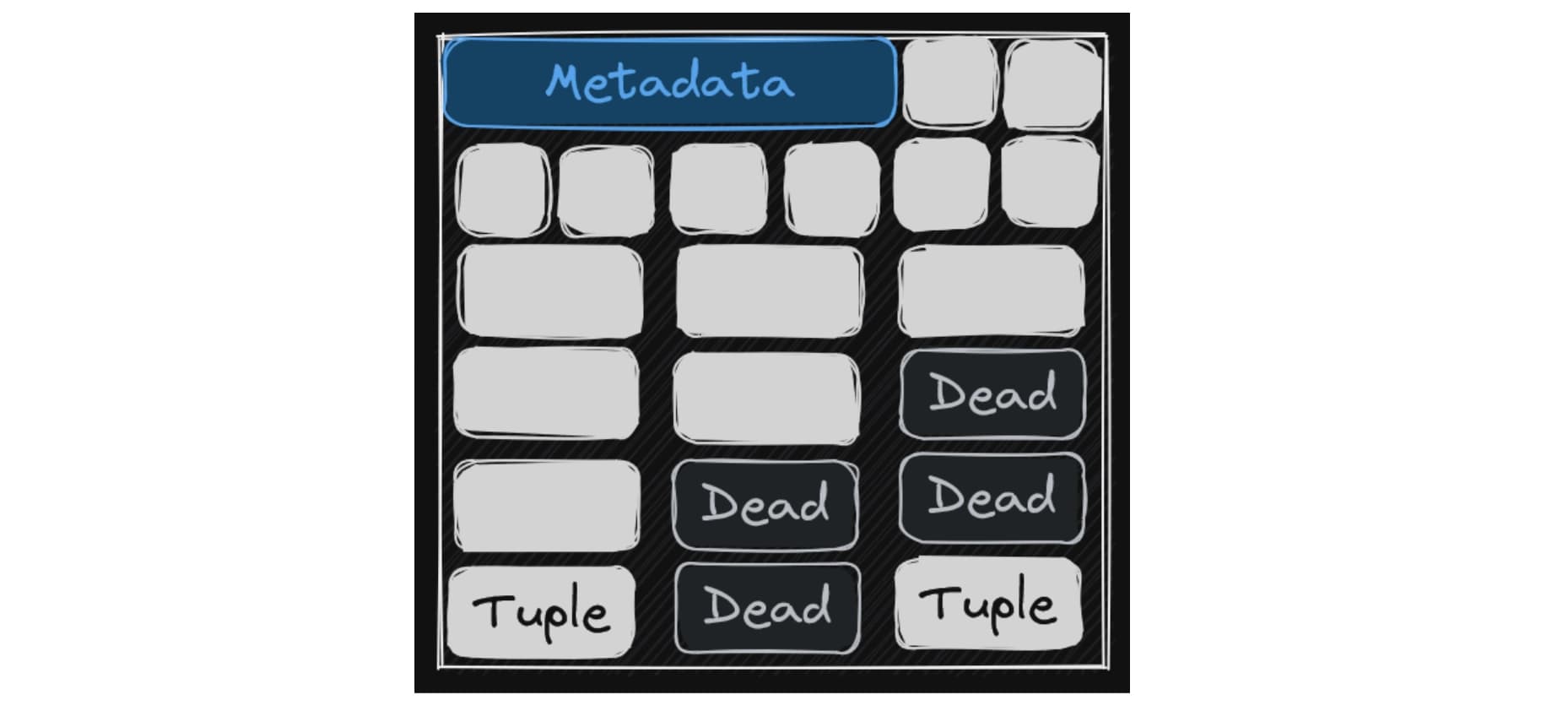
Đây là phần thú vị nhất. Khi chúng ta thực hiện các lệnh SQL, Postgres hành xử khác với suy nghĩ thông thường:
- INSERT: Tuple mới được ghi vào một Page còn trống.
- DELETE: Postgres không xóa ngay lập tức dữ liệu khỏi ổ cứng. Nó chỉ đánh dấu tuple đó là “đã chết” (Dead Tuple - unavailable).
- UPDATE: Thực chất là một tổ hợp của
DELETE(dòng cũ) +INSERT(dòng mới). Dòng cũ trở thành Dead Tuple, dòng mới được ghi vào vị trí khác.
Tại sao lại thiết kế như vậy? Đây là cơ chế của hệ thống MVCC (Multi-Version Concurrency Control). Việc giữ lại các “xác” dữ liệu cũ cho phép Postgres quản lý transaction, hỗ trợ rollback và đảm bảo tính nhất quán khi có nhiều kết nối cùng đọc/ghi một lúc (read consistency) mà không cần khóa (lock) quá chặt.
Hệ quả: Dead Tuples tích tụ dần theo thời gian.
Table Bloat là gì?
Table Bloat là hiện tượng xảy ra khi một bảng chứa quá nhiều Dead Tuples (dữ liệu rác) hoặc các Pages rỗng nhưng chưa được thu hồi. Mặc dù dữ liệu logic đã bị xóa, nhưng không gian vật lý vẫn bị chiếm dụng.
Cơ chế dọn dẹp:
- VACUUM: Quét và đánh dấu không gian của Dead Tuples là “có thể tái sử dụng” cho các dữ liệu mới. Tuy nhiên, nó không trả lại dung lượng cho hệ điều hành (OS). Kích thước file vật lý của bảng không giảm đi.
- Autovacuum: Daemon chạy ngầm để tự động kích hoạt VACUUM.

Kể cả sau khi đã thực hiện VACUUM, các trang dữ liệu đã được cleanup dead tuple, tạo ra các khoảng trống sẳn sàng cho việc INSERT/UPDATE dữ liệu. Cải thiện này ngay lập tức có thể nhìn thấy thông qua việc kích thước database ngưng phìn to.
Nhưng hiệu năng truy vẫn vẫn chưa cải thiện nhiều do hiện tượng data fragmentation vẫn diễn ra, toàn bộ page trống rỗng, chỉ tồn tại vài live tuple, và database vẫn phải tốn 20 IO để lấy vài dòng dữ liệu trong khi chúng hoàn toàn có thể tối giản hơn bằng cách sắp xếp lại bộ nhớ.
- VACUUM FULL: Viết lại toàn bộ bảng sang một file mới, loại bỏ hoàn toàn bloat và trả lại dung lượng cho OS. Nhược điểm: Nó yêu cầu khóa bảng (Exclusive Lock), gây downtime cho ứng dụng.
3. Tác động của Table Bloat lên Hiệu năng Database
Ngoài việc lãng phí dung lượng ổ cứng, Table Bloat gây ra những tác động nghiêm trọng đến hiệu năng database, đặc biệt là Cache Efficiency - một yếu tố quyết định tốc độ truy vấn.
3.1. Cache Efficiency và Tầm quan trọng
Cache Efficiency (Hiệu quả bộ nhớ đệm) là khả năng database giữ dữ liệu thường xuyên truy cập trong RAM để giảm thiểu I/O từ ổ cứng. Khi dữ liệu nằm trong cache, các thao tác đọc/ghi nhanh hơn đáng kể vì truy cập bộ nhớ nhanh hơn nhiều so với truy cập ổ cứng.
3.2. Tác động của Bloat lên Cache
Tăng Memory Usage (Lãng phí bộ nhớ)
Khi bảng và index bị bloat, chúng chiếm dụng nhiều không gian hơn mức cần thiết. Điều này dẫn đến:
- Memory cache chứa nhiều dữ liệu vô dụng: Các Dead Tuples và Pages rỗng vẫn được load vào RAM, chiếm chỗ của dữ liệu hữu ích.
- Giảm dung lượng cache hiệu quả: Cùng một lượng RAM, nhưng chứa ít dữ liệu thực sự cần thiết hơn. Ví dụ: Thay vì cache 1000 live tuples, bạn chỉ cache được 500 live tuples + 500 dead tuples.
Tăng Cache Miss Rate (Tỷ lệ cache miss cao hơn)
Cache miss xảy ra khi dữ liệu cần thiết không có trong cache, buộc database phải đọc từ ổ cứng:
- Cache bị “ô nhiễm” bởi bloat: Khi cache chứa quá nhiều dead tuples và fragmented pages, khả năng dữ liệu cần thiết bị đẩy ra ngoài (evicted) tăng lên.
- Tăng Disk I/O: Mỗi cache miss = một lần đọc từ ổ cứng, làm chậm query đáng kể. Với workload read-heavy, điều này có thể làm giảm throughput xuống 10-50 lần.
Giảm Effective Cache Size (Kích thước cache hiệu quả)
Effective cache size là lượng dữ liệu hữu ích thực sự nằm trong cache:
- Cùng một lượng RAM, ít dữ liệu hữu ích hơn: Bloat làm cho cùng một page (8KB) chứa ít live tuples hơn, dẫn đến phải load nhiều pages hơn để lấy cùng một lượng dữ liệu.
- Tăng tần suất eviction: Dữ liệu hữu ích bị đẩy ra khỏi cache thường xuyên hơn để nhường chỗ cho dữ liệu bloat, tạo ra một vòng lặp tiêu cực.
3.3. Tác động lên Query Performance
Query Execution Chậm hơn
- Queries phải đọc từ disk thay vì cache: Những query trước đây có thể được serve hoàn toàn từ cache, giờ phải đọc từ ổ cứng do cache miss.
- Complex queries bị ảnh hưởng nặng: Các query phức tạp với nhiều JOINs hoặc aggregations phụ thuộc rất nhiều vào efficient data access. Khi phải đọc nhiều pages bloat, thời gian execution có thể tăng gấp 5-10 lần.
Tăng I/O Operations
- Disk I/O là bottleneck chính: Mỗi cache miss = một disk read. Với bloat cao, số lượng I/O operations tăng đáng kể, làm chậm toàn bộ hệ thống.
- Sequential scans tốn kém hơn: Khi quét bảng, database phải đọc qua nhiều pages rỗng hoặc chứa dead tuples, lãng phí I/O bandwidth.
3.4. Tác động lên CPU Usage
Xử lý bảng và index bị bloat yêu cầu nhiều CPU resources hơn:
- Xử lý nhiều pages hơn: Database engine phải scan và process nhiều pages để tìm ra live tuples, tiêu tốn thêm CPU cycles.
- CPU saturation: Trong môi trường high-load, CPU có thể bị saturation do phải xử lý quá nhiều dữ liệu bloat, giảm resources cho các operations khác.
- Index traversal chậm hơn: Bloated indexes yêu cầu nhiều CPU để traverse và filter, đặc biệt với B-tree indexes lớn.
3.5. Tác động lên Maintenance Operations
Các thao tác bảo trì bị ảnh hưởng nghiêm trọng:
- VACUUM chậm hơn: VACUUM phải quét và xử lý nhiều dead tuples hơn, tốn nhiều thời gian và resources. Trong một số trường hợp, VACUUM có thể chạy hàng giờ thay vì vài phút.
- REINDEX tốn kém: Rebuild indexes trên bảng bloat mất nhiều thời gian và có thể gây lock contention.
- Maintenance windows kéo dài: Thời gian bảo trì cần thiết tăng lên, ảnh hưởng đến availability và performance trong thời gian này.
- Autovacuum không theo kịp: Khi bloat tích tụ quá nhanh, autovacuum có thể không đủ nhanh để dọn dẹp, dẫn đến bloat ngày càng trầm trọng.
3.6. Tác động Cascade (Hiệu ứng dây chuyền)
Bloat không chỉ ảnh hưởng một bảng, mà có thể gây ra hiệu ứng dây chuyền:
- Shared buffers bị chiếm dụng: Khi nhiều bảng bị bloat, shared_buffers (shared memory pool) bị lấp đầy bởi dữ liệu vô dụng, ảnh hưởng đến toàn bộ database.
- WAL (Write-Ahead Log) tăng kích thước: Các thao tác VACUUM và maintenance operations tạo ra nhiều WAL records hơn, ảnh hưởng đến replication và backup.
- Backup/Restore chậm hơn: Khi backup, database phải copy cả dead tuples, làm tăng thời gian và dung lượng backup.
4. Các chiến lược giảm dung lượng Database (Technical Solutions)
Dựa trên cơ chế trên, đây là các phương pháp kỹ thuật để xử lý:
Phương pháp 1: Monitoring Dead Tuples và Cache Efficiency (Quan sát)
Không thể tối ưu thứ mình không đo lường. Extension pgstattuple cho phép “nhìn xuyên thấu” vào cấu trúc vật lý của bảng.
CREATE EXTENSION IF NOT EXISTS pgstattuple;
-- Kiểm tra tỷ lệ bloat
SELECT (dead_tuple_len * 100.0 / table_len) as dead_tuple_ratio,
(free_space * 100.0 / table_len) as free_space_ratio
FROM pgstattuple('ten_bang_can_check');
-- Kiểm tra cache hit ratio (tỷ lệ cache hit)
SELECT
schemaname,
relname,
heap_blks_read as disk_reads,
heap_blks_hit as cache_hits,
CASE
WHEN (heap_blks_hit + heap_blks_read) > 0
THEN round(100.0 * heap_blks_hit / (heap_blks_hit + heap_blks_read), 2)
ELSE 0
END as cache_hit_ratio
FROM pg_statio_user_tables
ORDER BY cache_hit_ratio ASC;
Query này giúp xác định chính xác bảng nào đang lãng phí tài nguyên nhất và bảng nào có cache hit ratio thấp (dấu hiệu của bloat ảnh hưởng đến cache).
Phương pháp 2: Tuning Autovacuum và Fillfactor (Tinh chỉnh)
Cấu hình mặc định của Autovacuum thường quá “hiền” (conservative) đối với các bảng có write throughput cao. Chiến lược là điều chỉnh settings cho từng bảng (per-table basis) để quá trình dọn dẹp diễn ra thường xuyên hơn, ngăn chặn bloat tích tụ.
-- Ví dụ: Kích hoạt vacuum khi có 200 dòng thay đổi thay vì chờ theo tỷ lệ %
ALTER TABLE my_table SET (autovacuum_vacuum_scale_factor = 0, autovacuum_vacuum_threshold = 200);
-- Điều chỉnh fillfactor để giảm page splits và bloat
-- Fillfactor = 90 nghĩa là để lại 10% không gian trống trong mỗi page cho UPDATEs
ALTER TABLE my_table SET (fillfactor = 90);
CREATE INDEX idx_name ON my_table(column_name) WITH (fillfactor = 90);Điều chỉnh fillfactor giúp giảm page splits trong indexes và tables, từ đó giảm bloat ngay từ đầu. Với bảng có nhiều UPDATEs, fillfactor = 80-90 là hợp lý.
Phương pháp 3: Reclaim Unused Pages (Tái cấu trúc không downtime)
Khi VACUUM thường là không đủ và VACUUM FULL gây downtime, giới kỹ thuật thường dùng pg_repack.
Extension này hoạt động bằng cách:
- Tạo một bảng mới.
- Copy dữ liệu từ bảng cũ sang bảng mới (loại bỏ bloat).
- Swap bảng mới thay thế bảng cũ. Tất cả diễn ra với minimal locking, an toàn cho môi trường Production.
Phương pháp 4: Index Hygiene (Vệ sinh chỉ mục)
Indexes cũng bị bloat và chiếm dụng không gian rất lớn. Sử dụng pg_stat_user_indexes để truy tìm các index “vô dụng” (ít hoặc không bao giờ được scan) để loại bỏ.
-- Query tìm các index có lượt scan dưới 50
SELECT relname AS table_name, indexrelname AS index_name,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size, idx_scan
FROM pg_stat_user_indexes
WHERE idx_scan < 50
ORDER BY pg_relation_size(indexrelid) DESC;
Phương pháp 5: Column Alignment (Sắp xếp bộ nhớ)
Một chi tiết rất “low-level” nhưng thú vị: Thứ tự cột ảnh hưởng đến dung lượng lưu trữ do cơ chế Data Alignment Padding của CPU/OS.
Nguyên tắc: Sắp xếp các cột theo kích thước data type từ lớn đến nhỏ (ví dụ: int8 -> int4 -> bool). Việc này giảm thiểu các khoảng trắng (padding) được chèn vào giữa các trường để căn chỉnh bộ nhớ, giúp row gọn hơn đáng kể.
Phương pháp 6: Data Retention Policy
Cuối cùng, giải pháp đơn giản nhất là xóa dữ liệu cũ. Đối với dữ liệu time-series (chuỗi thời gian), việc sử dụng Partitioning (hoặc Hypertables trong TimescaleDB) cho phép DROP PARTITION - một thao tác xóa dữ liệu tức thì ở mức file hệ thống, nhanh và sạch sẽ hơn DELETE rất nhiều (vì không sinh ra Dead Tuples).
Tổng kết
Table Bloat là một đặc tính kỹ thuật đi kèm với sự mạnh mẽ của MVCC trong PostgreSQL. Hiểu rõ vòng đời của một Tuple (Insert -> Update/Delete -> Dead Tuple -> Vacuum -> Reuse) và tác động của nó lên cache efficiency giúp chúng ta có những chiến lược bảo trì chủ động, thay vì bị động nâng cấp phần cứng.
Điểm then chốt: Bloat không chỉ là vấn đề về storage cost, mà còn là vấn đề về performance degradation thông qua việc giảm cache efficiency. Một database với cache hit ratio thấp sẽ phụ thuộc nhiều vào disk I/O, làm chậm toàn bộ hệ thống. Do đó, việc monitor và xử lý bloat kịp thời là critical để duy trì hiệu năng database ở mức tối ưu.